源码分析Redis数据结构之ZipList
一、背景
压缩列表是一个由特殊编码的连续内存块组组成,被设计用于节约内存的数据结构。它存储字节数组和整数两种类型的数据节点。
我在看完了《Redis设计与实现》压缩列表这一节以及阅读完ziplist.c源码中头部的注释,对压缩列表的设计有了较深的体会,Redis的设计者简直是把内存使用节约到了极致。今天写篇笔记,记录下学习心得,进一步加深理解。
二、ZipList的数据结构
我将压缩列表的数据结构分两部分介绍。第一部分为ZipList整体的布局,第二部分为ZipList节点的布局。
ZipList的数据结构不像其他数据结构以struct的形式存在,它只是一块连续的内存块,人为观念上将内存块分为若干固定大小的小内存块,每个小内存块都代表着各自的含义。源码位于/src/ziplist.c中。
首先先根据数据结构绘制出整体的结构图:
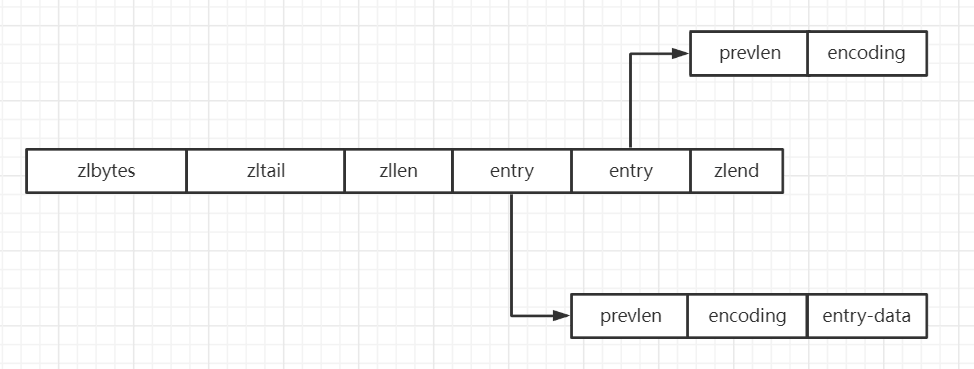
压缩列表的整体结构说明:
zlbytes: 记录了整个压缩列表占用的字节数, 包含了zlbytes字段本身, 在内存重分配的时候无需遍历整个列表计算旧压缩列表的字节数。占4字节大小。
zltail: 记录了压缩列表的表尾节点距离起始地址有多少字节, 获取表尾节点无需遍历整个列表。占4字节大小。
zllen: 记录了压缩列表中的节点个数, 当节点个数大于2^16-2时, 需要通过遍历整个压缩列表才能得到节点个数。占2字节大小。
entry: 表示压缩列表的节点,压缩列表可以包含多个压缩节点。
zlend: 特殊值 0xFF (十进制 255 ),用于标识压缩列表的末尾。占1字节大小。
压缩列表节点的结构说明:
- prevlen: 记录前驱节点的长度, 以字节为单位, 便于逆向遍历。
- encoding: 记录了当前编码的形式以及数据长度。
- entry-data: 保存了数据,可以是一个字节数组,也可以是一个整数,他们的大小取决于encoding。
注:当保存的数据为较小的整数时, 取值在1~12时,可以由encoding的低四位表示数值,这样就可以节省使用entry-data存储数值的内存空间。
未完待续~
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!