一、 背景 在看了一段时间的《Redis设计与实现》后, 是时候回头仔细阅读下Redis的源码, 写下自己的学习心得, 研究下源码中所体现的数据结构的设计思路。今天, 趁着工作之余, 阅读下SDS相关的源码,学习下SDS设计到的二进制安全、内存的申请分配过程、SDS的空间预分配和惰性空间回收、SDS中为什么采用内存不自动对齐的方式定义多类型的结构体。
二、 Redis的SDS数据结构 SDS的数据结构的源码位于/src/sds.h中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 struct __attribute__ ((__packed__ )) sdshdr5 {unsigned char flags; char buf[];struct __attribute__ ((__packed__ )) sdshdr8 {uint8_t len;uint8_t alloc;unsigned char flags;char buf[];struct __attribute__ ((__packed__ )) sdshdr16 {uint16_t len;uint16_t alloc;unsigned char flags;char buf[];struct __attribute__ ((__packed__ )) sdshdr32 {uint32_t len;uint32_t alloc;unsigned char flags;char buf[];struct __attribute__ ((__packed__ )) sdshdr64 {uint64_t len;uint64_t alloc;unsigned char flags;char buf[];#define SDS_TYPE_5 0 #define SDS_TYPE_8 1 #define SDS_TYPE_16 2 #define SDS_TYPE_32 3 #define SDS_TYPE_64 4 #define SDS_TYPE_MASK 7 #define SDS_TYPE_BITS 3 #define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T))); #define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T)))) #define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)
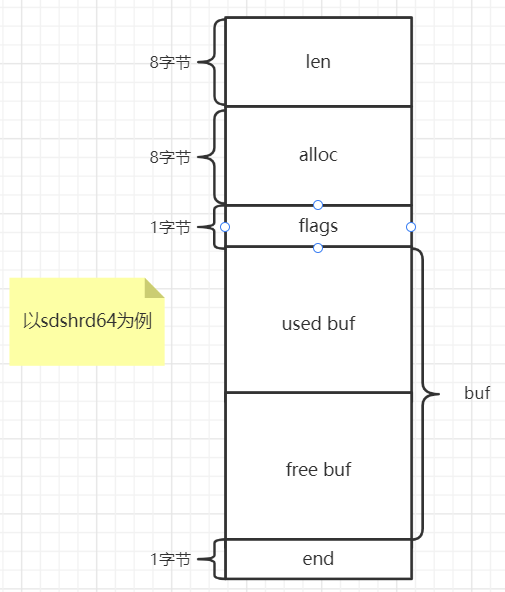
字段说明:
len:buf已使用的长度,长度小于等于alloc
alloc:buf分配的长度,包含used buf和free buf(未使用空间), 排除’/0’字符, 因为buf字符数组以’/0’的结束符。
flags:表示SDS_TYPE的标识, 在宏定义中可以看到, 目前最大64位上的TYPE标识为4, 对应二进制100,因此只用到3位, 有5位是用不到的。
buf:buf字符数组。
1.Redis中定义了5中类型的SDS, 其中sdshdr5不会被使用到, 其他类型主要依据CPU的位数及字符串的大小。
2.使用__attribute__ ((__packed__))定义结构体, 告诉编译器取消字节自动对齐, 让结构体按照紧凑的方式进行对齐, 占用内存, 常用于结构体动态发生变化的情景下, 具体的作用会在下面分析SDS初始化过程中详细讲解。
根据结构体定义, 我大致绘制了如下的数据结构图, 结合分析和代码可以更好的理解:
三、SDS初始化过程 SDS初始化函数源码位于/src/sds.c中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 sds _sdsnewlen(const void *init, size_t initlen, int trymalloc) {void *sh;char type = sdsReqType(initlen);if (type == SDS_TYPE_5 && initlen == 0 ) type = SDS_TYPE_8;int hdrlen = sdsHdrSize(type);unsigned char *fp; size_t usable;1 > initlen); 1 , &usable) :1 , &usable);if (sh == NULL ) return NULL ;if (init==SDS_NOINIT)NULL ;else if (!init)memset (sh, 0 , hdrlen+initlen+1 );char *)sh+hdrlen;unsigned char *)s)-1 ;-1 ;if (usable > sdsTypeMaxSize(type))switch (type) {case SDS_TYPE_5: {break ;case SDS_TYPE_8: {8 ,s);break ;case SDS_TYPE_16: {16 ,s);break ;case SDS_TYPE_32: {32 ,s);break ;case SDS_TYPE_64: {64 ,s);break ;if (initlen && init)memcpy (s, init, initlen);'\0' ;return s;
分析:
1.首先根据initlen初始长度, 计算出SDS类型编号, 如果类型是SDS_TYPE5, 则转为SDS_TYPE8, 并根据类型计算出结构体的大小hdrlen。
2.申请一块大小为initlen + hdrlen + 1字节大小的内存空间sh, sh指向内存块的首地址,initlen对应的是buf字符数组的初始长度, 额外加1是因为buf字符数组以’\0’结尾标识字符串的结束。
3.接着计算得到buf的首地址为sh + hdrlen,并由s指针指向。
4.得到了buf首地址之后,由于SDS的结构体采用__attribute__ ((__packed__))关键字定义,取消了内存自动对齐, 所以在计算flags内存地址时无需考虑不同类型的字段在内存对齐时带来字节差异。fp = ((unsigned char*)s)-1,只需后移sizeof(char),即1字节的地址,就可得到flags的内存地址,这便是内存不自动对齐带来的好处之一, 不需要对类型进行多个if判断处理。如果采用内存对齐, 在不知道类型编号的情况下,计算flags内存地址将变得非常复杂,性能开销也许比内存不对齐的方式更大。
5.最后计算出buf分配的空间大小,由usable-hdrlen-1得到, usable为申请到的内存空间的大小, 减去结构体的大小,再减去一个’\0’字符大小,即得到buf字符数组的大小。其中buf字符数组包含了used buf 和free buf,free buf源于空间预分配和用于惰性空间回收。最终再根据类型编号,对sh的剩余字段进行初始化,返回指向buf首地址的指针s。
注:结合上面的数据结构图有助于理解。
四、SDS的空间预分配和惰性回收机制(扩缩容) 空间预分配:
空间预分配用于优化SDS的字符串增长过程, 减少修改字符串时带来的内存空间重分配次数。
惰性回收机制:
惰性回收机制用于优化SDS的字符串缩短过程, 将缩短产生的空间归到buf free未使用空间中去, 不立即执行内存重分配,同样减少修改字符串时带来的内存重分配次数。
首先来看空间预分配,由于空间预分配的分配过程发生于SDS的扩容过程, 因此我们可在sdsMakeRoomFor函数中目睹到空间预分配的真容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 sds sdsMakeRoomFor (sds s, size_t addlen) {void *sh, *newsh;size_t avail = sdsavail(s);size_t len, newlen, reqlen;char type, oldtype = s[-1 ] & SDS_TYPE_MASK;int hdrlen;size_t usable;if (avail >= addlen) return s;char *)s-sdsHdrSize(oldtype);if (newlen < SDS_MAX_PREALLOC)2 ;else if (type == SDS_TYPE_5) type = SDS_TYPE_8;1 > reqlen); if (oldtype==type) {1 , &usable);if (newsh == NULL ) return NULL ;char *)newsh+hdrlen;else {1 , &usable);if (newsh == NULL ) return NULL ;memcpy ((char *)newsh+hdrlen, s, len+1 );char *)newsh+hdrlen;-1 ] = type;-1 ;if (usable > sdsTypeMaxSize(type))return s;
分析:
1.首先会去判断buf free未使用空间是否充足,如果充足, 则无须扩容;否则计算出新的buf大小newlen(不包含free未使用空间)。根据newlen大小, 选择合适的空间预分配机制,存在以下两种:
当newlen的大小小于1M, 额外申请同样newlen大小的free未使用空间,,此时得到的buf总空间大小为2newlen + 1B。1B为\0的大小。
当newlen的大小大于等于1M,额外申请1M大小的free未使用空间,此时得到的buf总空间大小为newlen + 1M + 1B。
2.在计算得到总的buf后, 再根据buf大小计算出新SDS的type类型,当type不改变,复用旧SDS的内存空间上,在其基础上扩充内存大小至hardlen+newlen+1, 反之, 重新申请大小hdrlen+newlen+1的空间,将数据从旧的SDS拷贝到新的SDS, 回收旧SDS的内存资源。
3.SDS的动态扩容机制根据扩容前后的大小决定是否复用原SDS的内存空间。
4.由于SDS使用内存不对齐方式定义结构体, 因此对flags及buf地址的计算直接采用的是指针偏移方式。
SDS的缩容过程如下,目的是重分配内存, 去除free未使用空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 sds sdsRemoveFreeSpace (sds s) {void *sh, *newsh;char type, oldtype = s[-1 ] & SDS_TYPE_MASK;int hdrlen, oldhdrlen = sdsHdrSize(oldtype);size_t len = sdslen(s);size_t avail = sdsavail(s);char *)s-oldhdrlen;if (avail == 0 ) return s;if (oldtype==type || type > SDS_TYPE_8) {1 );if (newsh == NULL ) return NULL ;char *)newsh+oldhdrlen;else {1 );if (newsh == NULL ) return NULL ;memcpy ((char *)newsh+hdrlen, s, len+1 );char *)newsh+hdrlen;-1 ] = type;return s;
五、SDS与普通的C字符串的区别 1.SDS能在O(1)的时间复杂度内得到字符串长度
C字符串往往以char []字符数组的形式表示, 因此要计算字符数组的长度的时间复杂度为O(N)。而SDS具备len字段,可以在O(1)的时间复杂度内得到字符串的长度。
2.SDS可以动态扩缩容字符串的长度,避免了C字符串可能引发的缓冲区溢出问题。
缓冲区溢出是指发生在两个内存地址相邻的C动态字符数组上,在执行字符串拼接操作时,前一个字符串地址空间会溢出到后一个字符串的地址空间上,导致后一个字符串数据被修改。
3.SDS是二进制安全的
我理解的二进制安全是指对输入的任何字节都能够正确的处理,包含特殊字符,如'\0',转移字符等。因为SDS中定义了len字段,从而不用担心在字符串中间出现'\0',会将其判断为字符串的末尾。
六、SDS采用内存不自动对齐的方式定义结构体 在上文的分析中,已经谈到了SDS为什么使用__attribute__ ((__packed__))将结构体声明为内存非自动对齐。那么首先简单聊聊内存自动对齐,当访问未对齐的内存时,处理器需要做两次甚至多次内存访问,而对齐的内存访问只需要一次,便于CPU的快速访问。而在Redis的SDS中多类型结构体的场景下, 使用内存不自动对齐, 可以方便、高效地通过指针的偏移, 不用过多关注结构中字段的类型, 计算出flags和buf的内存地址。