源码分析Redis数据结构之字典
一、 背景
最近入手了一本书,《Redis的设计与实现》,在工作的闲暇之际,不断学习,持续给自己充能。在阅读前,拉了GitHub上的源码,准备结合这源码进行阅读。在阅读到字典的实现这一章节,回想起之前分析Python字典实现的源码过程,字典的数据结构存在着些许相似和不同。特此做一篇笔记分析下Redis字典涉及的数据结构及使用场景,对比Python的字典,有哪些不同的地方。
注:
1.本篇文章分析的Redis源码基于6.2.6 stable版本
2.源码分析Python的Dict关联式容器
二、 Redis字典的数据结构
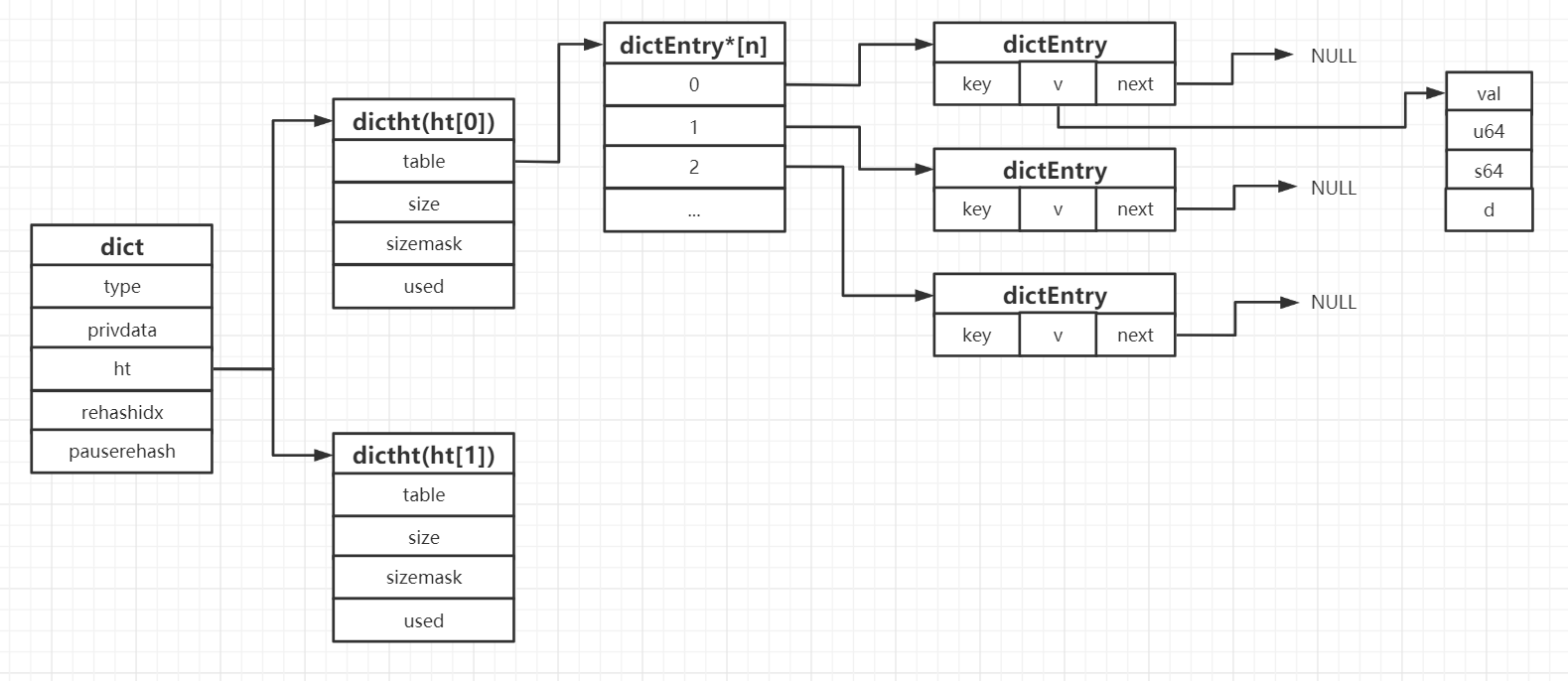
源码位于/src/dict.h头文件中,从最顶层的数据结构逐层往里分析,涉及有三个重要的数据结构。首先使dict结构体,源码如下:
1 | |
然后来看下具体hash表的结构体:
1 | |
最后来看
1 | |
根据如上的数据结构,可绘制如下的数据结构图:
三、Redis的Rehash操作
看完了redis基本的数据结构, 接下来解读下redis rehash的源码。dictRehash函数源码位于/src/dict.c中
1 | |
说明:
1.redis rehash的过程发生在ht[0]和ht[1]两个hash表项上,通过rehashidx值确定ht[0]上需要进行rehash的槽位。redis rehash的过程中实际是节点对象的指针迁移的过程。由于redis使用链地址法解决hash冲突,因此需要遍历每个槽位上的单链表, 重新计算节点在ht[1]上的槽位, 并采用头插法的方式重构冲突链。
2.在rehash完后,需要检查是否所有节点都已经rehash完,如果rehash完毕,则释放ht[0]中的哈希表内存资源。
3.我在看《Redis的设计与实现》一书中渐进式rehash章节时, 根据源码重新梳理了一下渐进式rehash的过程。
详细过程如下:
- 首先根据
dictRehash函数在dict.c中搜索调用者, 在dictAddRaw,dictGenericDelete,dictFind,dictGetRandomKey,dictGetSomeKeys这些函数中会执行渐进式rehash过程,即在对字典执行插入、删除、查找、随机获取等操作方法时, 会进行rehash。 - dict->rehashidx属性会记录当前ht[0]中正在执行rehash的索引槽位, 并伴随整个rehash始终。当dict->rehashidx == -1时, 标志rehash完成或未开始。
- redis的渐进式rehash过程中采用分治的思想,每当执行一次字典的相关操作时, 会首先将ht[0]哈希表在rehashidx槽位上的所有键值对rehash到ht[1]上,重新构成冲突链, 然后执行正常操作, 这样避免集中式rehash带来的大量计算以及短暂性阻塞服务器。
- 当在未来的某个时间点, ht[0]哈希表上所有的键值对都已经rehash到ht[1], 此时回收ht[0]上哈希表的资源, 将ht[1]作为ht[0], 将rehashidx属性重设置为-1。
四、Python字典和Redis字典在数据结构上的异同点
不同点:
1.键对象和值对象的基本类型:
- 在Python中,万物皆对象,每个对象都是基于PyObject结构体上进行实例化,因此键对象和值对象都是PyObject类型。
- 在Redis中,大部分对象, 例如dict的key和val都是基于C语言中的数据类型。
- 因此字典对象在内存上占用的空间也不同。
2.处理hash冲突的方式:
- 在Python中,采用的是直接定址法,计算下一个槽位的地址采用线性探测+对象的hash值结合计算,使得发生冲突的可能性减小。
- 在Redis中,采用拉链法,将同一槽位的键值体对象以链式结构,存储在同一槽位上。相比于直接定址法,hash冲突发生的可能性更小,但由于每个键值对实体之间由指针链接起来,因此需要额外的内存空间存放指针。
3.扩缩容方式:
- Python中的扩缩容并不会基于原对象实现,而是申请一块合适大小的新对象。并将原对象上的键值对对象依次拷贝过去, 均摊后时间复杂度为O(1),但当发生扩容时,时间复杂度增长到O(N), 因此当扩容容量较大时, 会消耗更多的CPU资源。扩容机制往往是翻倍扩容。
- Redis中的扩缩容基于原对象实现, 发生在ht[0]和ht[1]两个哈希表上, 允许渐进式rehash, 当开始rehash后, 每次dict操作都会触发ht[0]哈希表上指定rehashidx值对应的槽位上的所有键值对进行rehash, 像增加操作会添加到在ht[1]哈希表上。时间复杂度为O(1)。由于渐进式rehash将扩缩容操作均分到每个dict操作上, 因此rehash过程不会明显占用CPU资源, 不会短暂性阻塞服务器。
4.垃圾回收机制:
- 语言的垃圾回收机制往往较复杂, 在Python中存在三种垃圾回收机制, 以引用计数为主, 标记清除和分代回收为辅。
- Redis的垃圾回收机制主要通过引用计数的方式进行资源回收, 当引用计数为0时, 标记对象不被任何其他对象引用, 可安全回收。引用计数字段为
refcount, 在redisObject结构体中定义。例如HSET game name Wizard3,game为hash表对象, 其最终会封装为redisObject对象, ptr指向字典对象的地址空间, type和encoding决定dict采用ziplist还是hashtable编码实现, refcount记录着该对象被多少其他对象引用。
相同点:未完待续~
五、总结Redis的dict
1.Redis字典的使用场景很广泛, 在阅读Redis db的数据结构中, 发现Redis的数据库其实是由字典组成, 主要由dict和expires两个字典组成, 前者负责保存存储在某db空间上的所有键值对,后者保存某db空间上所有键的过期时间戳, 因此对数据库的相关操作都是建立在字典操作之上的。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!