深入探究GIL的利与弊
深入分析Python全局解释器锁GIL的利与弊
一、GIL的诞生背景
在谈GIL之前,先补一波线程的知识,正好最近再复习操作系统:
 {width=100%}
{width=100%}
在那个单核盛行的时代,自多线程问世以来,线程成为了处理机调度最基本的单位。很多语言都开始着手处理线程并发的问题。其中python之父Guido在1992年8月4号引入了GIL的概念。那么那时候为什么要引入GIL全局解释器锁呢?
比方你申请了计算机的某些资源,用来创建一些Object,等到你用完了这些资源后,是不是要归还这些资源,这样才能够取之有度,用之不竭。
在线程引入之前,只有进程的时候,CPU调度每次只能运行一个进程,也就是单核无论如何也不能并行运行多个进程。而线程的出现,则被称之为“微进程”,在进程中进一步划分空间,增加并发度,减小进程切换带来的开销,但随之而来也出现了一些问题,那就是多线程并发的结果的不确定性。
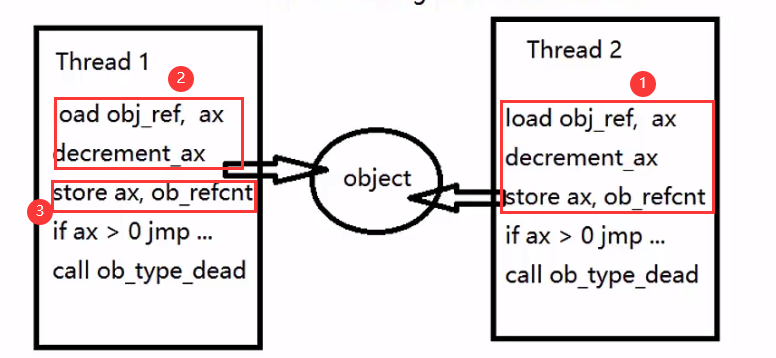
以下面两个线程回收资源为例进行说明:
 {width=90%}
{width=90%}
分析:
Python中垃圾回收机制不同于Java,它采用的引用计数的方式,当计数器为0,则表示某资源已不被任何对象引用,因此可以回收该资源。
如图所示是汇编指令,因为高级语言可能一条语句就会对应很多条汇编指令。我们就看前三条。首先将ax加载到obj_ref,也就是引用技术,然后执行ax-1,最后保存ax。
假设此时引用计数为2,要回收这两个资源,假设thread1先运行到了2步骤,紧跟着thread2运行了1步骤,因为他们是并发的,同时这些指令也不是原子性的。所以根据并发的不确定性,是有一种可能,让thread2保存了减一后得到的引用计数,剩余引用计数为1时,thread1那里显示的仍然是回收thread2中资源前的引用计数值2。这样就会导致资源回收的问题。
因此GIL全局解释器锁的出现是为了解决资源回收的引用计数的问题。当然GIL锁在后来与其他语言组合的时候,为了方便的管理资源的分配问题,例如与C语言结合,诞生了科学计算包Numpy等,也有着相应的好处。
二、GIL的定义及存在的好处
之前谈到了GIL的出现主要是为了解决多线程中资源回收的引用计数的问题,以及为了方便管理与多语言结合的资源的分配问题。那么这把锁又和现在的一般的锁,例如分布式锁,共享锁等等的区别又在哪?
经过一番寻找资料,发现GIL锁其实是定义在很底层的位置,它是一把底层的,基于字节码级别的互斥锁,这样确保了同一时刻只有拿到这把唯一的GIL锁的线程才能够上处理机进行调度。GIL存在的好处就是节省了加锁解锁带来的内存性能开销. 同时由于这把字节码级别的锁存在,在Python虚拟机中的每条字节码指令都是线程安全的.举个例子,例如list.append操作,使用dis模块查看字节码执行过程,可以发现append是内建名字空间中的一个名字,其占用了一个字节码,同时其回调了底层了的C语言函数app1,即这个app1函数是线程安全的.因而append操作也是线程安全的.而list,dict的一系列操作都是线程安全的.
三、GIL的存在的坏处
GIL基于bytecode定义在底层的位置,早已根深蒂固,我猜想当时guido可能没有意识到多核发展的如此之快,没有完全考虑到多核情况下GIL的巨大局限—–无法充分利用CPU资源。
Python的线程调度参考了操作系统的时间片调度算法, 只不过Python中的线程调度的时间片以一个字节码为单位,执行了一定数量的字节码就会产生线程调度.
因为Python中每个线程进入调度都有一个字节码计数器,类似操作系统中的时间片,当执行完一定数量的字节码,将释放GIL锁并唤醒其他线程。而执行CPU密集型的任务的时候,会导致线程调度多次,因此多线程正常情况下会比单线程产生更多的线程调度的时间消耗。如果在多核上跑多线程任务,也会导致CPU利用率很低,接下来我会用代码和CPU资源图来分析。
四、单线程,多线程,多进程,进程池的CPU密集型任务举例
下面是一个很简单的比较例子,用了求解质数来模仿cpu密集型,其实求之前刷leetcode的时候,还有一种时间复杂度更小的求解质数的方法(埃拉托色尼筛选法),不过这里先不谈。
1 | |
我的操作系统如下:
 {width=90%}
{width=90%}
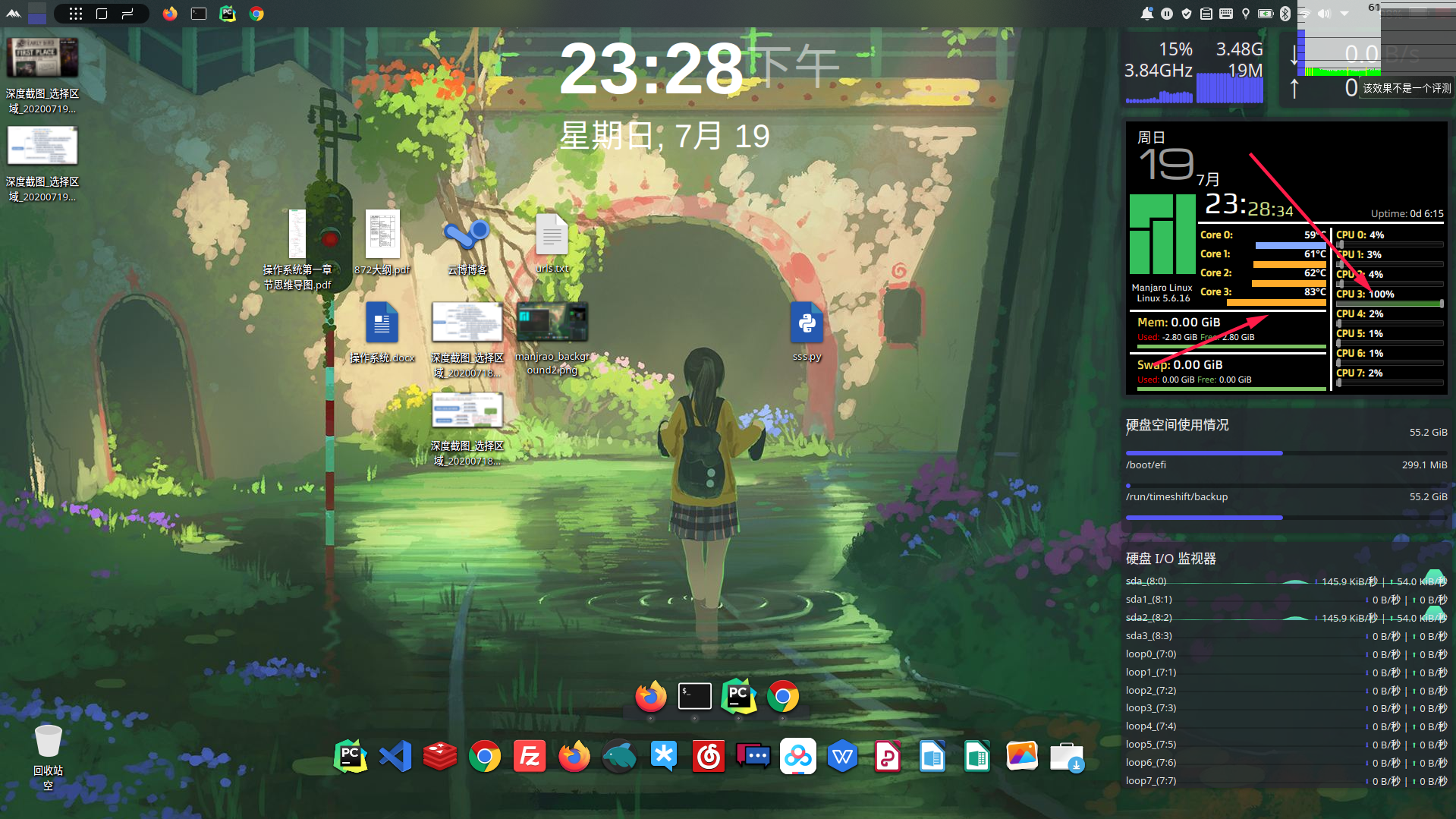
单进程单线程的CPU运行效果如下:
 {width=100%}
{width=100%}
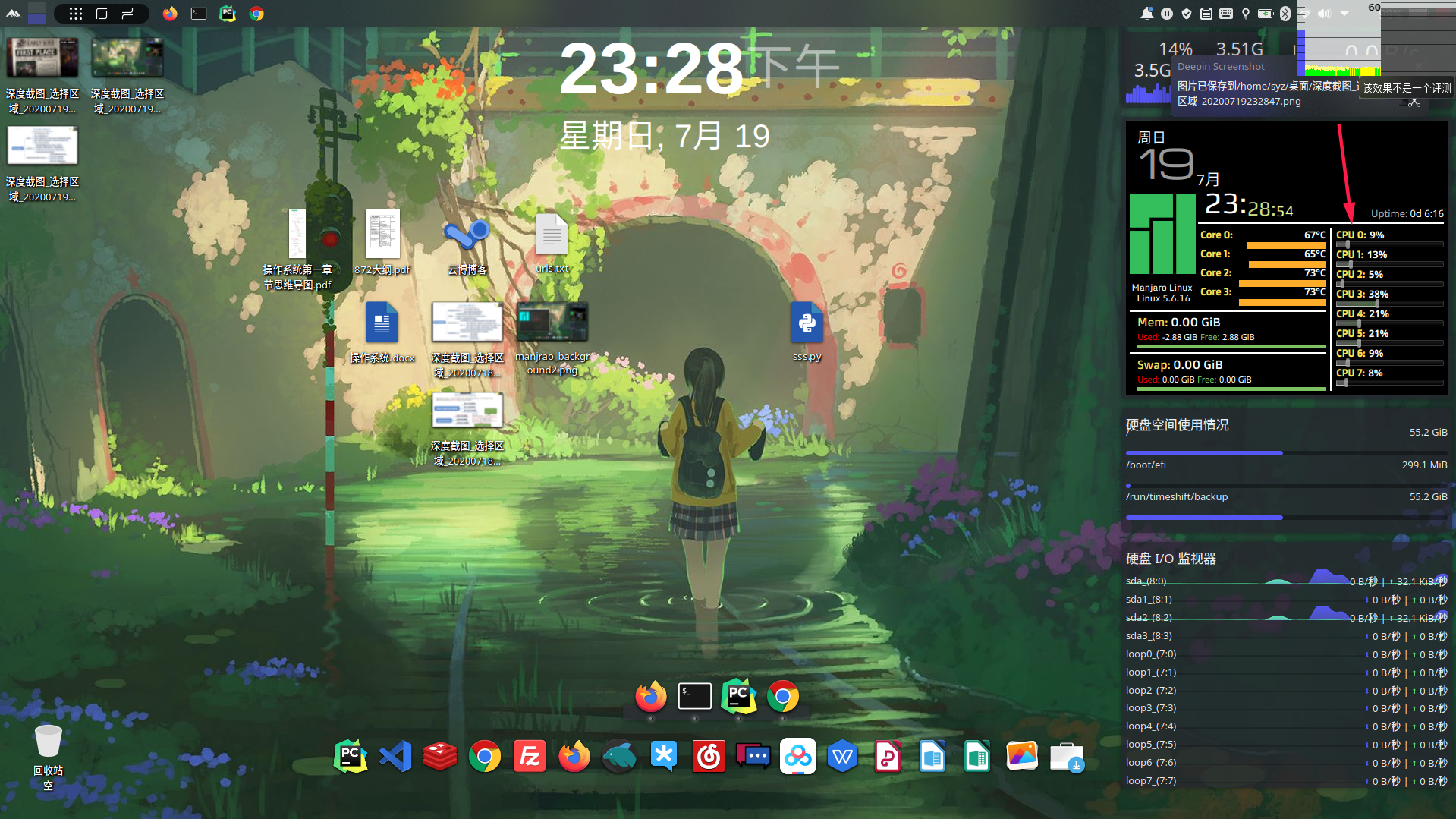
多线程单进程的CPU运作如下:
 {width=100%}
{width=100%}
多进程CPU运作如下:
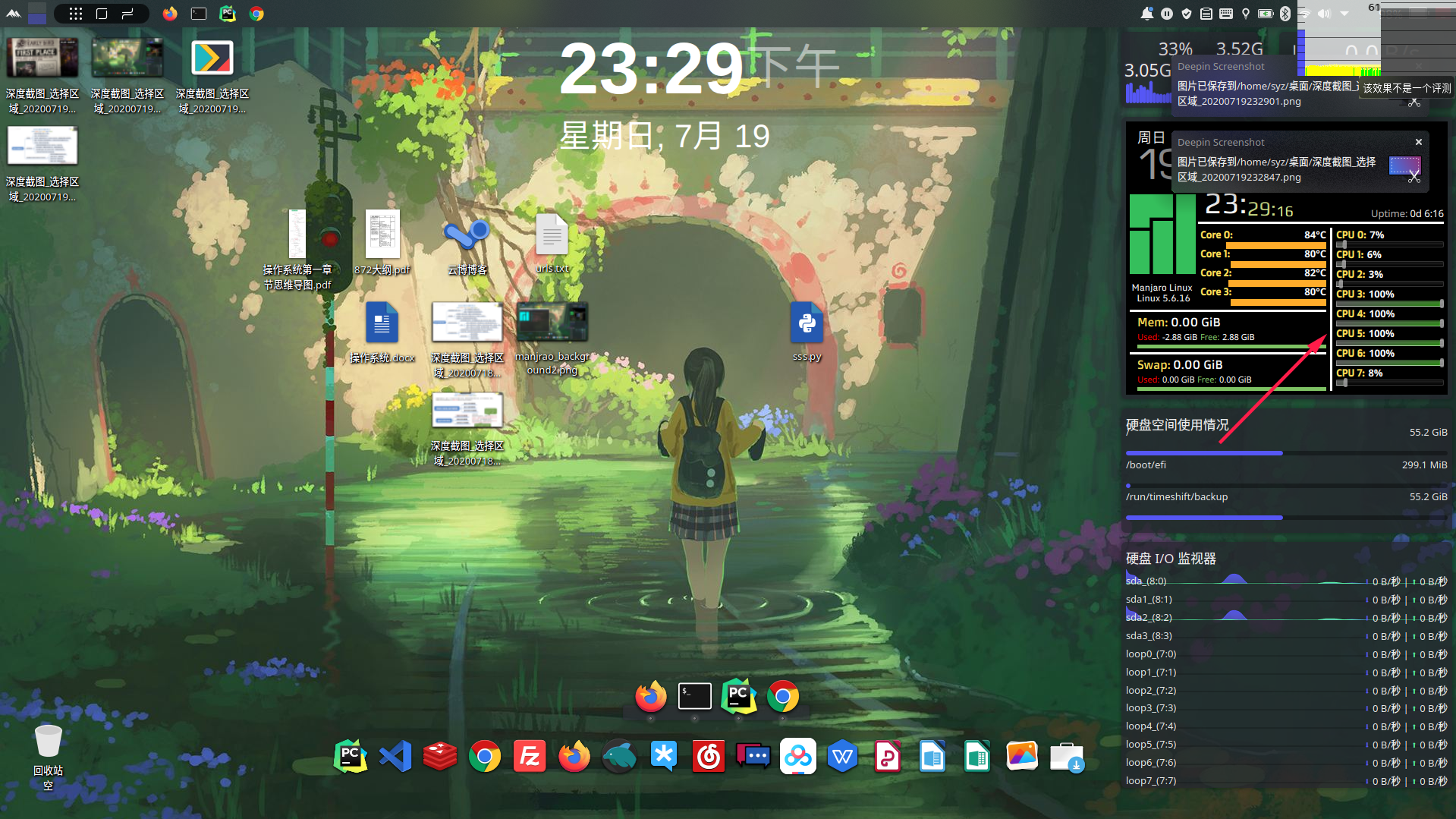 {width=100%}
{width=100%}
进程池的CPU运作如下:
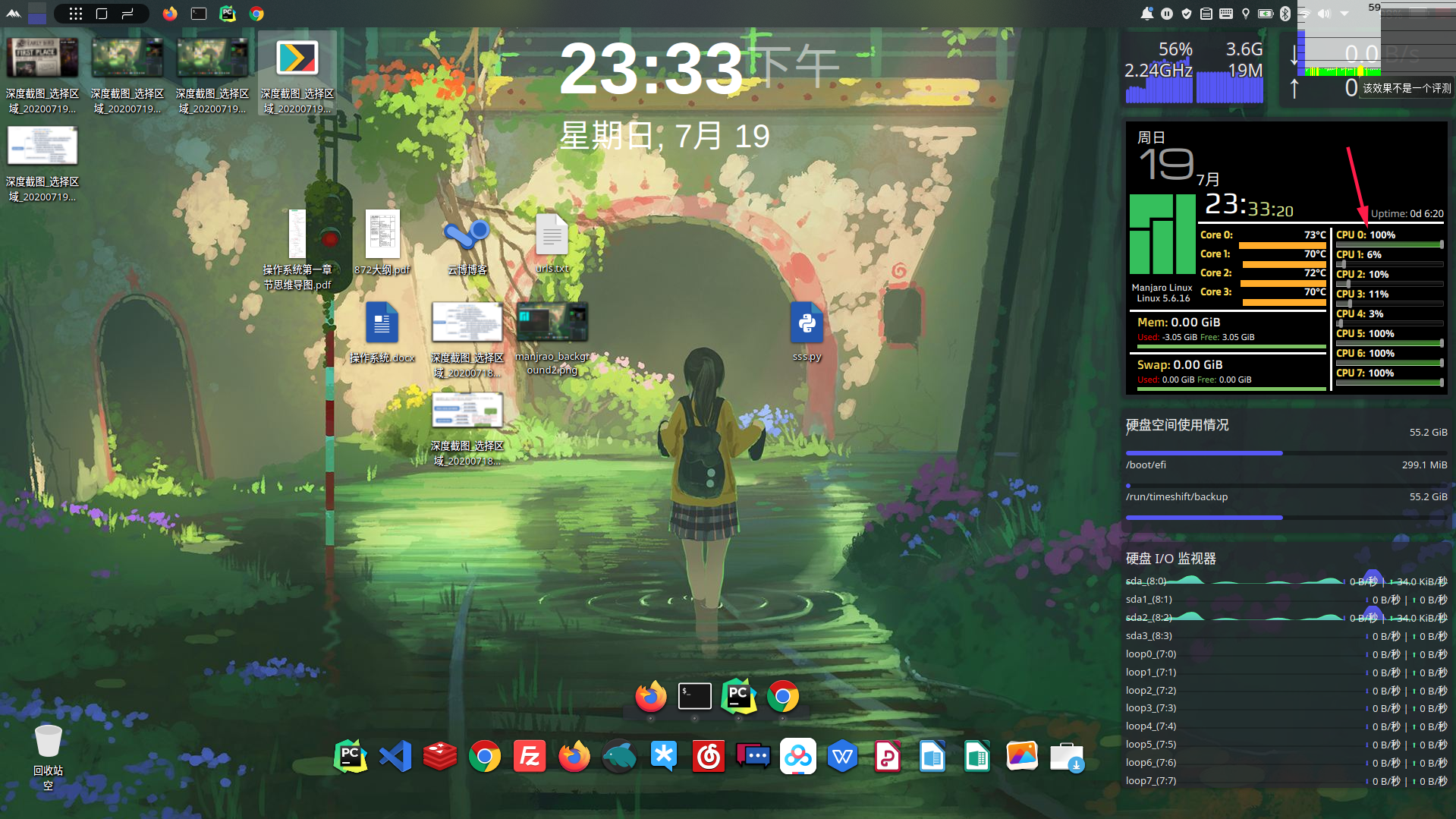 {width=100%}
{width=100%}
消耗时间如下
CPU密集型下同步所需要的时间: 30.59021615982056
CPU密集型下多线程所需要的时间: 31.321476459503174
CPU密集型下多进程所需要的时间: 8.955211162567139
CPU密集型下进程池所需要的时间: 10.86313271522522
结论
我测了5次,可以初步判断,CPU密集型下多线程并不一定比单线程所花费的时间少,而采用多进程以及进程池可以有效的减少时间。因此可以认为Python对于CPU密集型的处理使用多进程要比多进程好的多。
原因分析:
刚才上面已经谈到了GIL锁,它的存在仅针对线程而不是进程,它在解决了垃圾回收问题的计数问题,但是也带来了额外的性能问题,因为同一时间只有一个线程可以拿到这把GIL全局解释器锁,拿到锁的线程就会进入Pyhon虚拟机执行,但是中每个线程都记录了自己执行了多少个字节码,也可以理解为一个计数器ticks,当ticks达到一定数量之后,就需要进行线程(进程)的调度,调度的过程由操作系统底层完成,修改其状态位,而正式这种CPU密集型的任务(请看多线程的那副图),导致了线程调度的次数大大增加,也并没有完全利用CPU资源,进而带来更多的切换开销。尽管统一个进程间的线程不断的切换,虽然不需要切换进程的。的运行环境,但是切换次数太多,开销仍然很大,并不比单线程效率高,而罪魁祸首正是这把GIL锁!!
当然对于CPU密集型使用多线程的问题,一般替换成多进程就行了!
下次做个I/O对比的例子,这次就先到这,不早了,命要紧~
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!